BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding by Devlin, J., Chang, M., Lee, K., Toutanova, K. ArXiv, 2018
This paper was published last year by Google to advance work on pre-trained natural language representations. Their main contribution was to advance the state-of-the-art results on most language model evaluation tasks. The key improvement came from training their unsupervised model on a new task (word masking) and using a model that looks at text from back-to-front as well as front-to-back.
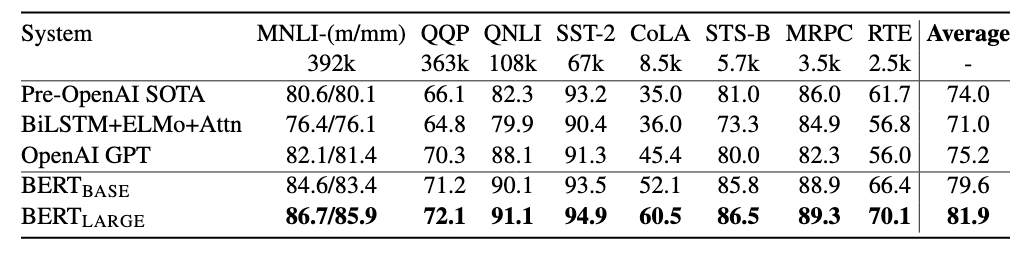
Against previous models like OpenAI’s GPT the new BERT model makes improvements on all eleven tasks in what is known as the General Language Understanding Evaluation (GLUE) benchmark. It came to my attention because of how it completely upended the leaderboard of the question-answering challenge, SQuAD 2.0. After the BERT paper was published every single one of the top submissions was redone with BERT and experienced significant gains.
The language representation problem
A language model can represent ideas about languages by building mathematical representations of the individual words and relationships between them. Since most machine learning models used to solve natural language processing tasks require a vector representation of the data, we can build specific vectors that make solving the tasks easier. That is what BERT aims to do.
First models might try to simply represent the words used by a one-hot encoding on the entire dictionary of words. Word embeddings like word2vec and GloVe further improve on this representation by fixing the size of the vectors much smaller and training them so that the cosine similarity between vectors represents the linguistic or semantic similarity between them.
BERT is a further extension of this that changes the vector embedding for a word based on the context in which it appears. A model like GloVe will give the word “toy” the same vector in each situation, while BERT might differentiate it depending on the usage. For example:
They bought the child a toy.
I will toy with that idea.
These sentences use toy in two different ways that require different representations.
Using this learned representation, models can predict the next word in a sentence or classify sentiment in a phrase with much greater accuracy. Some of the other tasks that can be performed include: named entity recognition (finding people and places), sentence entailment classification (is it a contraduction, an entailment, or neutral), paraphrasing, grammar acceptability prediction, and sentence similarity prediction.
Pre-training tasks
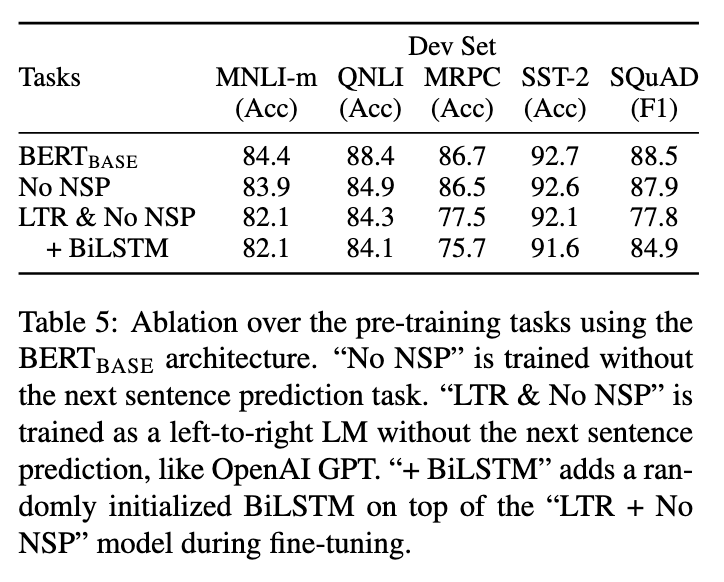
The BERT model is pre-trained on two unsupervised prediction tasks: masked language model and next sentence prediction.
The masked language model task is very important because it helps with training bi-directional transformers. Pre-training the bidirectional model on masked LM makes a 2-11% improvement in accuracy on tasks compared with a left-to-right only task (which also aren’t trained on the second task).
1. Masked language model
This task improves the representation of words within a sentence by having the model guess what a missing word should be. The training set consists of many sequences of words where 15% of the tokens in each sequence are manipulated.
For each chosen word one of three manipulations is applied:
- 80% of the time the word is simply masked
- 10% of the time it is replaced with a random word
- 10% of the time it is left unchanged
The authors justify this method:
The Transformer encoder does not know which words it will be asked to predict or which have been replaced by random words, so it is forced tokeep a distributional contextual representation ofeveryinput token. Additionally, because random replacement only occurs for 1.5% of all tokens (i.e., 10% of 15%), this does not seem to harm the model’s language understanding capability.
They also believe it to be the most important part of the model:
One of our core claims is that the deep bidirectionality of BERT, which is enabled by masked LM pre-training, is the single most important improvement of BERT compared to previous work.
2. Next sentence prediction
This helps improve the representation of relationships between sentences. They split a training set of sentences into pairs of sentences where 50% of the time the second sentence is the actual next sentence and the other 50% it is a randomly selected other sentence from the text.
Bi-directional transformers
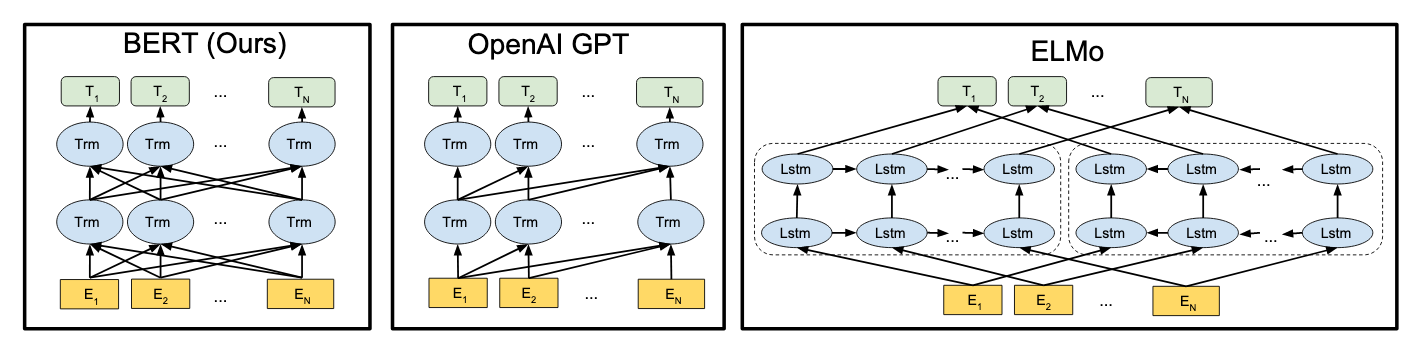
The BERT model takes advantage of the Transformer architecture which has suplanted recurrent neural networks (RNNs) and Long-Short Term Memory (LSTM) units in particular as the primary method for solving sequence to sequence problems.
The authors explore the effect of model size on their success. They use almost 1.5 times as many parameters (340M) than the previous largest Transformer (235M) reported in their largest model. They also mention using a larger training dataset than OpenAI GPT. Scaling up the size of the data and model contributes to the empirical improvements they have shown.
Further Research
The BERT paper does not dive into many of the results beyond the empirical successes on standard language modeling banchmarks. It would be interesting to look at what cases the model fails to predict. Would there be common failures? Additionally, do the choices about input representation and bi-directional analysis also have similar success in other languages besides english?
In the meantime, it seems BERT will become a successful fixture of many language models for solving NLP tasks.